ডেটা সায়েন্স প্রজেক্ট আইডিয়া বাস্তবায়নের ধাপসমূহ
এই পোষ্টে আমি ডেটা সায়েন্স নিয়ে যারা আগ্রহি তাদের জন্য একটি প্রজেক্টের আইডিয়া শুরু করা থেকে এর পূর্ণ বাস্তবায়নের প্রকৃয়া সম্পর্কে ধারণা দেয়ার চেষ্টা করব। এই আর্টিকেল যখন লিখছি তখন বাংলাদেশের মানুষ ভোট দেয়ার জন্য প্রস্ততি নিচ্ছে। ডিসেম্বর ৩০ তারিখ, ২০১৮। বাংলাদেশে অনুষ্ঠিত হবে গণভোট।
আইডিয়া
আমাদের দেশে যে সরকারই ক্ষমতায় থাকুক না কেন বিরোধী দলের উপর সরকার তথা সরকার সমর্থক দলের দমনপীড়ন একটি নিত্য ঘটনা। বিশেষ করে নির্বাচনের আগে এর মাত্রা বেড়ে যায় বহুগুনে। তবে এ নিয়ে সংখ্যাতাত্বিকভাবে কাজ হয়েছে কমই। অধিকার নামের এনজিও মানবাধিকার বিষয়ক পরিসংখ্যান রিপোর্ট আকারে প্রকাশ করে।
এর বাইরে অনেক কিছু করা সম্ভব। বিশেষ করে ইন্টারনেটে বাংলা ভাষায় অনেকগুলো জনপ্রিয় পত্রিকা এখন নিয়মতান্ত্রিকভাবে খবর প্রকাশ করে যাচ্ছে। এই ডেটা ব্যবহার করে ছড়িয়ে থাকা তথ্যগুলোকে আমরা সামারি আকারে প্রকাশ করতে পারি।
কোন পরিকল্পনা বাস্তবায়নের আগে সেটি কীভাবে করা হবে তার একটি পূর্নাঙ্গ থাপনসমূহ লিখিত আকারে সাজাতে হয়। নীচে সেরকম একটি চিত্র দেখান হল।
হাইপোথিসিস
প্রথমেই আসে কী করতে চাই সে প্রশ্ন। প্রশ্নের আসলে কোন অভাব নেই। চারপাশে অনেক প্রশ্ন, ইচ্ছে করলেই একটা বেছে নেয়া যায়। আপনার মন মত একটি প্রশ্ন ঠিক করে এগুতে পারেন।
যেমন ধরুন সরকার দাবি করছে বিরোধী দলের উপর কোন রকম দমনপীড়ন করা হচ্ছে না। অন্যদিকে সরকারি দলের নেতা কর্মীরাও দাবি করছে যে তাদের নেতা কর্মীরাই বরং আক্রমনের স্বীকার হচ্ছে।
আপনি এটিকেই আপনার হাইপোথিসিস ধরে কাজ শুরু করতে পারেন। একটি বিষয় পরিষ্কার করে নেই যে এই হাইপোথিসিসকে পরিসংখ্যানের হাইপোথিসিস টেষ্টের মত করে আমারা টেষ্ট করতে পারি আবার সিম্পলি কিছু পরিসংখ্যান দিয়ে একটা তুলনামূলক চিত্রও তুলে ধরতে পারি। কাজের স্কোপ কী হবে সেটি আপনি আগে থেকে ঠিক করে নিবেন।
সম্ভাব্য হাইপোথিসিস
সমস্যা মোটামুটি চিহ্নত হওয়ার পর আপনাকে হাইপোথিসিস-এর স্টেইটমেন্ট আকারে লিখতে হয়। যেমন–
বিরোধীদলের উপর সরকারি দলের সদস্যদের দমন পীড়নের মাত্রা সরকারি দলের নেতা কর্মীদের উপর বিরোধী দলের কর্তৃক দমন পীড়নের মাত্রার চেয়ে বেশী।
প্রশ্ন হলো এই দমন পীড়ন কীভাবে পরিমাপ করা হবে। পরিমাপের এই মেট্রিক আমাদের প্রথমেই ঠিক করতে হবে।
একটি উপায় হতে পারে যে কতবার আক্রমন করা হয়েছে সেটি। আবার হতে পারে আক্রমনের পর হতাহতের সংখ্যা। কিংবা হতে পারে মোট আক্রমনের শতাংশের দায় কার কতটুকু। এরকম নানা ভাবে এই মেট্রিক ডিফাইন করা যেতে পারে।
রিফাইন্ড হাইপোথিসিস
মেট্রিক নির্ধারন হলে পরে হাইপোথিসিসটিকে আমরা রিফাইন করব।
বিরোধীদলের উপর সরকারি দলের সদস্যদের দমন পীড়নের আনুপাতিক হার (প্রপরশন) সরকারি দলের নেতা কর্মীদের উপর বিরোধী দলে কর্তৃক দমন পীড়নের আনুপাতিক হার (প্রপরশন)-এর চেয়ে বেশী।
পরিসংখ্যানের ভাষায় লিখতে গেলে নাল হাইপোথিসিস হবে – দুই গ্রুপের মধ্যে মার খাওয়ার অনুপাতের মধ্যে পার্থক্য নেই। অর্থাৎ এদের অনুপাত সমান। আর অলটারনেটিভ হাইপোথিসিস নানা ভাবে ধরা যেতে পারে। একমুখি হাইপোথিসিস এই ক্ষেত্রে বাস্তবসম্মত; যেটি হবে – বিরোধী দলের কর্মীদের মার খাওয়ার অনুপাত সরকারি দলের কর্মিদের মার খাওয়ার অনুপাতের চেয়ে বেশী।
ডেটা কালেকশন
হাইপোথিসিস অনুযায়ি আমাদের ডেটাতে দরকার হবে কতগুলো সহিংসতার ঘটনা ঘটেছে তার পরিসংখ্যান এবং কোন দল কতবার আক্রান্ত হয়েছে তার সংখ্যা।
কিন্তু ডেটা কোথায় পাব?
ডেটা দুই ভাবে পাওয়া যেতে পারে। প্রথমত কেউ ডেটা সংগ্রহ করেছে তার কাছ থেকে নিতে পারি। এ জন্য আপনাকে লিটারেচার রিভিউ করতে হবে। আমাদের দেশে যেহেতু এ ধরনের কাজ খুব একটা হয়না সেজন্য লিটারেচার রিভিউ করে বিশেষ কিছু পাওয়া যাবে বলে মনে হয় না। বরং দেশের ভিতরে কোন অর্গানাইজেশন বা সরকারি সংস্থা কর্তৃক প্রকাশিত রিপোর্টকে ভিত্তি ধরে এগুনো যেতে পারে।
এভেইলেবল ডেটা দিয়ে যদি প্রশ্নের উত্তর পাওয়া না যায় তাহলে নিজেদেরই ডেটা সংগ্রহ করতে হবে।
নিজেরা সংগ্রহ করতে হলে হয় আমাদের দৈনিক পত্রিকার ওয়েবসাইটে গিয়ে ম্যানুয়ালি খবরগুলো সংগ্রহ করতে হবে। আর ম্যানুয়ালি করতে না চাইলে কম্পিউটার প্রোগাম লিখে পুরো ব্যাপারটা অটোমেশনের মাধ্যমে করতে হবে।
ম্যানুয়ালি কাজটি করতে গেলে আমাদের অনেক সময় লাগবে এবং কাজটিতে অনেক ভুল ভ্রান্তি হওয়ার সম্ভাবনা থাকবে। যে কারণে অটোমেশনের মাধ্যমে করাটা ভালো হবে। কীভাবে সেটি বাস্তবায়ন করা যাবে তার একটি আউটলাইন দিচ্ছি।
ডেটা কালেকশন পদ্ধতি
যে কোন ডেটা কালেকশন অটোমেইট করার আগে আমাদের মনে রাখতে হবে গবেষণার উদ্দেশ্য এবং কী মেট্রিক আমাদের প্রয়োজন সেগুলো। প্রয়োজনীয় ডেটা যেন বাদ না যায় আর অপ্রয়োজনীয় ডেটা সংগ্রহ করার পিছনে যেন সময় নষ্ট না হয়। অর্থাৎ যতটুকু তথ্য আমাদের দরকার ঠিক ততটুকুই সংগ্রহ করা।
অনেক সময় ডেটা এমনভাবে সংগ্রহ করা হয় যে একই ডেটা পরবর্তী গবেষষণায় ব্যবহৃত হবে। সেক্ষত্রে ডেটা কালেকশনের স্কোপ বাড়ানো যেতে পারে।
ডেটা এলিমেন্ট
ধরা যাক আমরা সিদ্ধান্ত নিলাম যে অটোমশন স্কৃপ্ট দিয়ে পত্রিকার ওয়েবসাইট থেকে ডেটা সংগ্রহ করব। পত্রিকার সাইটে অনেক খবর থাকে যা থেকে প্রজেক্টের জন্য দরকারি তথ্য আলাদা করে খুঁজে পাওয়া সহজ নয়। ইংরেজী ভাষায় ন্যাচারাল ল্যাঙ্গুয়েজ প্রসেসিং অনেক অগ্রসর হলেও বাংলা ভাষায় সেরকম কাজ এখনো হয়নি। তাই ন্যাচারাল ল্যাঙ্গুয়েজ প্রসেসিং এলগরিদগুলো দিয়ে বাংলা ডকুমেন্ট ক্ল্যাসিফিকেশন ততটা সহজে করা যায় না। বরং বাস্তব সম্মত লক্ষ্য হবে কিছুটা অটোমেশন আর কিছুটা ম্যানুয়াল ইনপুটের মাধ্যমে ডেটা সংগ্রহ করা।
ফ্লো-চার্টের মাধ্যমে ডেটা কালেকশনের সম্ভাব্য ধাপসমূহ আমি দেখিয়েছি।
পুরো ব্যাপারটকে সিম্পল রাখতে চাইলে আমরা শুধুমাত্র আর্টিকেলের শিরোনামগুলো সংগ্রহ করতে পারি। এটি খুব সহজেই ওয়েব স্ক্রেপিং এর মাধ্যমে করা সম্ভব।
প্রথমেই আপনাকে ঠিক করতে হবে কোন পত্রিকা থেকে সংবাদগুলো সংগ্রহ করবেন। একটি সোর্স থেকে সংগ্রহ করলে আপনার কাজ অনেকটাই সহজ হয়ে যাবে কেননা ডুপ্লিকেট খবর নিয়ে চিন্তা করতে হবে না। একাধিক সোর্স থেকে নিলে আপনাকে ম্যানুয়ালি ডুপ্লিকেটগুলো বাছাই করে সেগুলো থেকে একটিকে গণনা করতে হবে।
এরপর সেই পত্রিকার আর্কাইভ সেকশন থেকে প্রতি দিনের খবরগুলোর শিরোনাম কম্পিউটার প্রোগ্রামের মাধ্যমে স্ক্রেইপ করে একটি সিএসভি বা এক্সেল ফাইলে সংগ্রহ করা যায়। এর পর ম্যানুয়ালি শুধুমাত্র নির্বাচন সংশ্লিষ্ট সহিংসতার খবরগুলোকে বিশেষ কোন ট্যাগ দেয়া যাতে এদেরকে ফিল্টার করে আলাদা করা যায়।
এরপর মেট্রিক অনুযায়ি যতগুলো ডিসক্রিট ফিল্ড যোগ করা দরকার ততগুলো কলাম সেই ফাইলে যোগ করব। ধরি একটি কলামের নাম victim, যার সম্ভাব্য মান হতে পারে A অথবা B। আপনি ইচ্ছে হলে অন্য ভাবেও ক্যাটেগরাইজ করতে পারেন। আমি একটি উপায় দেখালাম।
তাহলে আপনার ডেটার কলামগুলো এরকম দেখাতে পারে। আমি কাল্পনিক একটি ডেটার প্রথম দুই লাইন দেখাচ্ছি। স্মরণ করা যেতে পারে victim কলামটি খবরের শিরোনাম পড়ে ম্যানুয়ালি পূরণ করতে হবে। ডেটা সিমুলেট করা হয়েছে অগাষ্ট থেকে ডিসেম্বর ২৯, ২০১৮ পর্যন্ত।
| date | title | victim |
|---|---|---|
| 2018-08-01 | শিরোনাম | B |
| 2018-11-01 | আরেকটি শিরোনাম | B |
| 2018-11-01 | আরেকটি শিরোনাম | A |
| 2018-11-01 | আরেকটি শিরোনাম | A |
| … | ||
| … | ||
| 2018-12-29 | B |
ডেটা এনালিসিস
ডেটা কালেকশন হয়ে গেলে একে আমাদের প্রসেস করতে হবে। এই প্রসেসিংএর ধাপটি একটি ভিন্ন রকম কেননা আমাদের ডেটা হলো টেক্সট যা পত্রিকার ওয়েবসাইট থেকে প্রোগ্রাম লিখে স্ক্রেইপ করা হয়েছে। ফলে প্রাথমিক ক্লিনিং এর ধাপটি আমাদের পার করে আসতে হবে।
এই প্রজেক্টে আমাদের উদ্দেশ্য যদি হয় শুধুমাত্র সহিংসতার ফ্রিকোয়েন্সির তুলনা করা তাহলে সে মোতাবেক ডেটাকে সামারাইজ করে ফেলব। স্ট্যাটিসটিকস-এর যে কোন সফটওয়্যার দিয়েই ডেটা এনালিসিস এর কাজ করা যাবে। আমি R দিয়ে করছি। কোড ও দিয়ে দিচ্ছি।
প্রথমেই আমরা কাল্পনিক কিছু ডেটা তৈরী করবো। তারপর সেটি গ্রাফের মাধ্যমে দেখাব।
কাল্পনিক ডেটা
আসুন প্রথমেই কাল্পনিক ডেটা তৈরি করি। গবেষণার ক্ষেত্রে এরকম কাল্পনিক ডেটা তৈরী করাকে সিমুলেশন (simulation) বলে। আমরা কাল্পনিক ডেটা তৈরী করছি এটাকে বলা হবে ডেটা সিমুলেট করছি।
library(lubridate)
# If you use this seed, your results will be same as mine
# i.e., results are reproducible
set.seed(19)
# Generate sequence of dates between Aug 1 and Dec 29th, 2018
dt = ymd("2018-08-01") + days(0:150)
# Randomly sample (to replicate some dates) from this sequence
dt <- sample(dt, size = 2000, replace = TRUE)
# Generate the victim (A, B) using a given probability
# We generate three sets of data with varrying probability
# and size
victim1 <- sample(c("A","B"), 100, replace=TRUE, prob = c(0.3,0.7))
victim2 <- sample(c("A","B"), 400, replace=TRUE, prob = c(0.2,0.8))
victim3 <- sample(c("A","B"), 1500, replace=TRUE, prob = c(0.1,0.9))
# Combining the data sets to make a single data set
victim <- c(victim1, victim2, victim3)
# Check the proportion of samples by victim type
prop.table(table(victim))## victim
## A B
## 0.128 0.872এরপর তারিখ এবং সেই তারিখের ভিক্টিম এই কলাম দুটিকে একত্র করে আমরা ডেটা সেটটি তৈরী করব এবং ডেটার প্রথম ১০ টি সারি দেখাব।
df = cbind.data.frame(dt, victim)
head(df, 10)## dt victim
## 1 2018-08-18 B
## 2 2018-10-13 B
## 3 2018-11-07 B
## 4 2018-08-11 A
## 5 2018-09-25 A
## 6 2018-09-03 A
## 7 2018-09-14 B
## 8 2018-10-26 B
## 9 2018-12-05 B
## 10 2018-11-18 Aএখন আমাদের গণনা করতে হবে প্রতি দিন কয়জন ভিক্টিম A দলের এবং কতজন B দলের। তারপর সেটি চিত্রের মাধ্যমে দেখাব।
library(tidyverse)
df_victim <- df %>%
group_by(dt, victim) %>%
summarise(
n = n()
)
ggplot(df_victim, aes(x = dt, y = n, color = victim)) +
geom_line() +
ggtitle("Number of victims by party affiliation by day") +
xlab("Date") + ylab("Number of Victims")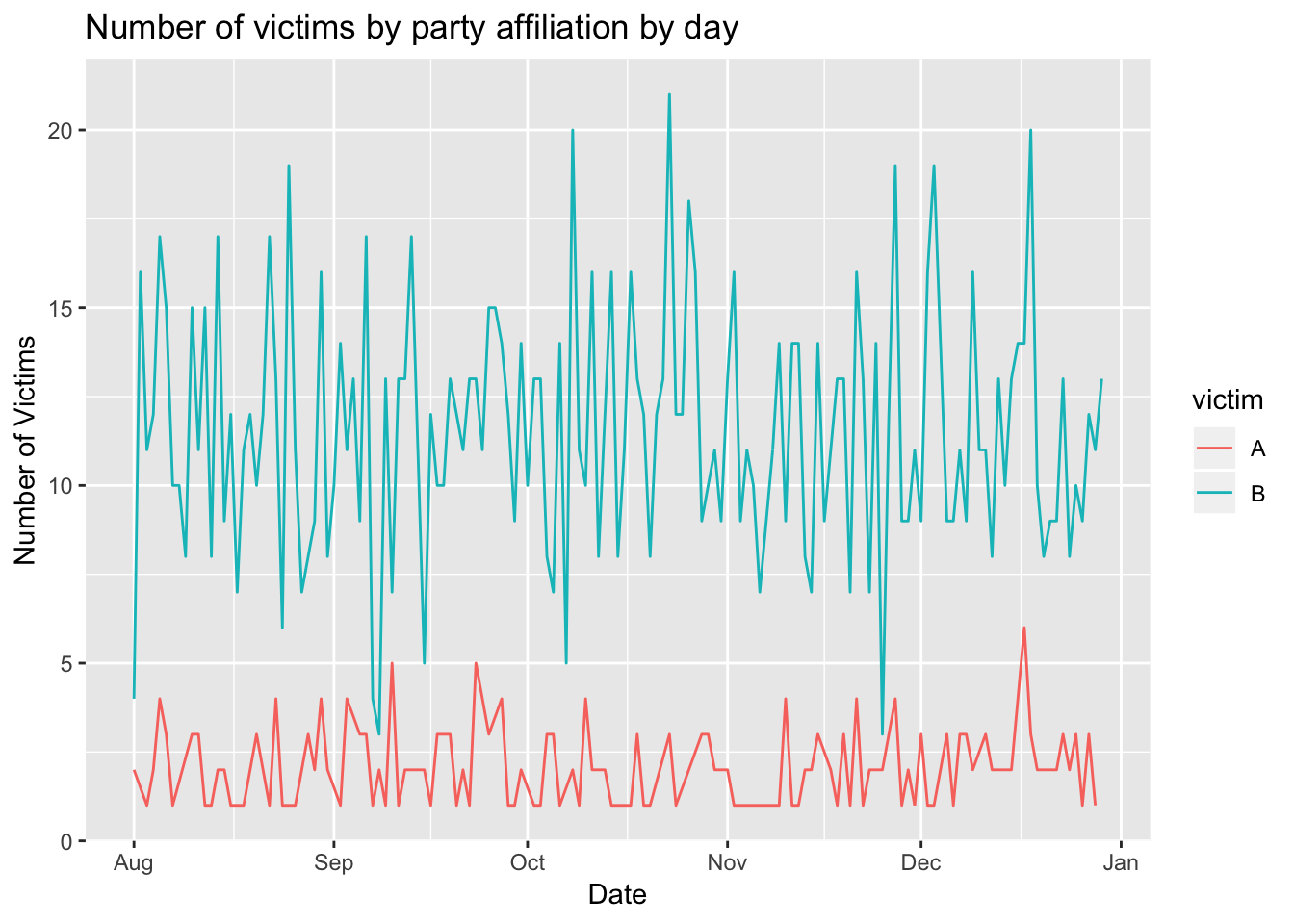
উপরের চিত্রে পার্টি ভেদে দৈনিক আক্রান্তের সংখ্যা দেখানো হয়েছে। দেখা যাচ্ছে B দলের লোকজন বেশি আক্রান্ত হয়েছে। এটি কাল্পনিক ডেটার তথ্য। আসল ডেটাতে এই সংখ্যা কী হবে সেটি ডেটা থেকেই জানা যাবে।
অনেক সময় গত কয়েক মাসে মোট কতজন আক্রান্ত হয়েছে সেটির ক্রমযোজিত সংখ্যা আমরা জানতে চাইতে পারি। তার জন্য ডেটাকে একটুখানি পরিবর্তন করতে হবে যা নিচের কোড দিয়ে দেখানো হল। এখানে প্রতি দিন পার্টি ভেদে যত সংখ্যক আক্রান্ত হয়েছে তাদের ক্রমযোজিত ফল বা cumulative total বের করা হয়েছে। সেটি cn ভ্যারিয়েবলে স্টোর করা হয়েছে।
df_cumulative <- df_victim %>%
group_by(victim) %>%
arrange(dt) %>%
mutate(
cn = cumsum(n)
)
ggplot(data = df_cumulative, aes(x = dt, y = cn, col = victim)) +
ylab("Cumulative Number of Victims") +
xlab("Date") +
geom_line(aes(y = cn))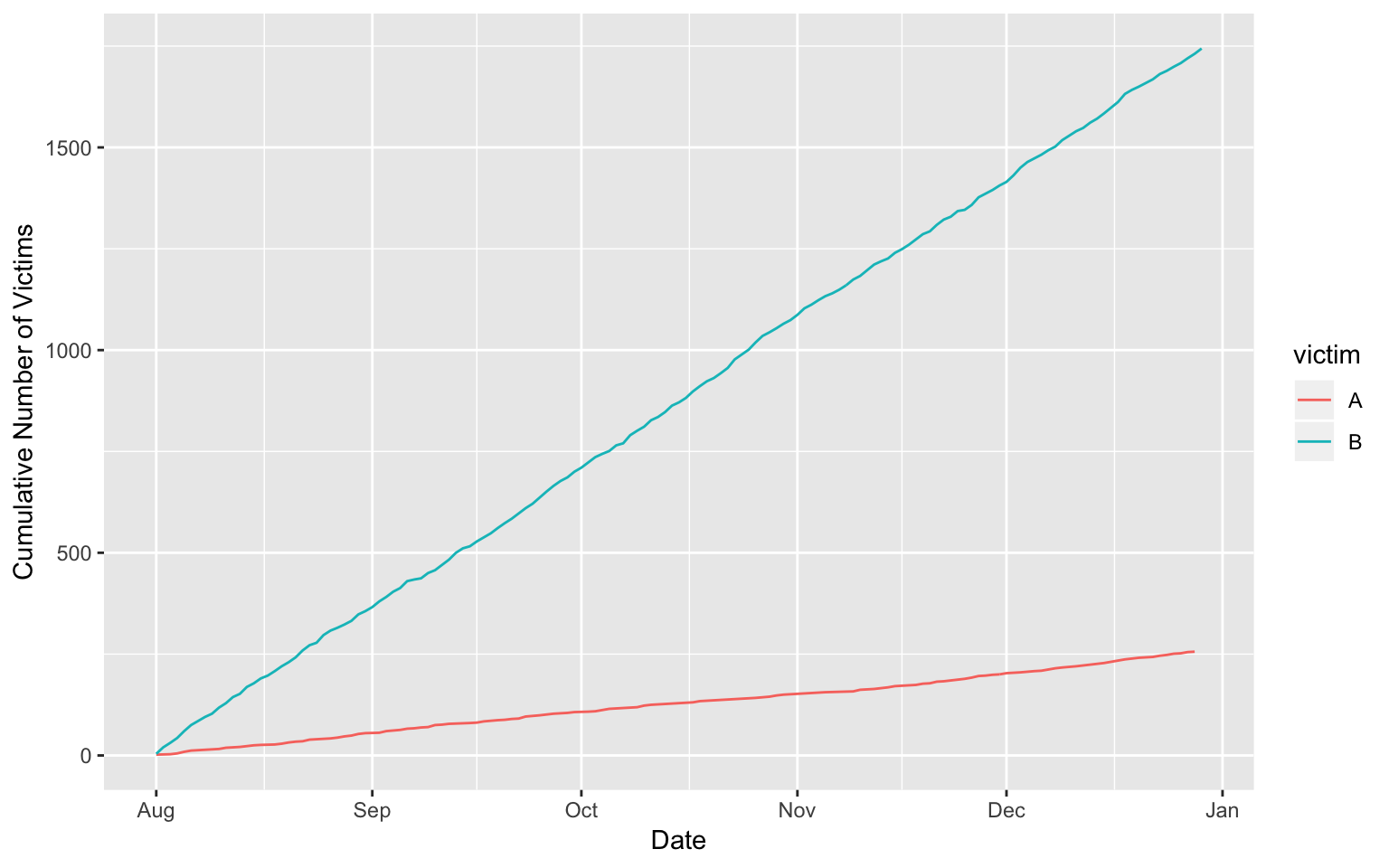
ডিসকাশন/আলোচনা
এই ধাপে ফলাফল বিশ্লেষণ করতে হবে এবং পাঠকের উপযোগি করে লিখতে হবে। যথাসম্ভব টেকনিক্যাল টার্মগুলো পরিহার করে সহজবোধ্য করে লিখতে হবে। অনেক ক্ষেত্রে সংবাদপত্রে প্রকাশের উদ্দেশ্য থাকলে তার জন্য আলাদা করে একটি প্রেস রিলিজ তৈরী করতে হবে। পরিশেষে ডেটার কোন সীমাবদ্ধতা থাকলে তা প্রকাশ করতে হবে। মূল উদ্দেশ্য থাকবে যেন পাঠকের মনে বিভ্রান্তি সৃষ্টি না হয়।
পরিসংখ্যানের এবিউজ ও মিসইউজ করা যেন লক্ষ্য না হয় সেদিকে খেয়াল রাখতে হবে।
শেষ কথা
এই আর্টিকেলের উদ্দেশ্য ছিল ডেটা সায়েন্সের কোন প্রজেক্ট কিভাবে অর্গানাইজ করতে হয়। প্রত্যেকটি প্রজেক্ট অন্য প্রজেক্ট থেকে যথেষ্ট আলাদা হয় কিন্তু মূল গঠন এরকমই। অনেক ক্ষেত্রে হাইপোথিসিস টেস্টের পার্টটি থাকে না। সেক্ষেত্রে কেবল ডেসক্রিপ্টিভ সামারি দিয়েই কোন রিপোর্ট হতে পারে। স্ট্যাটিসটিক্যাল টেস্ট করার জন্য প্রয়োজনীয় এসাম্পসন ঠিক আছে কিনা সেগুলো আগে যাচাই করে দেখতে হবে।